Забудьте Excel: автоматический парсинг цен, отзывов и трендов для анализа рынка
Маркетинговая разведка давно вышла за рамки “сверки пары цен вручную”. В реальности нужно регулярно собирать сотни и тысячи карточек: цену, наличие, доставку, скидки, отзывы и сигналы спроса - и получать не просто таблицу, а понятные выводы: где конкурент демпингует, у каких товаров растет негатив, какие темы “выстреливают”.
С современными библиотеками и облачными сервисами все это можно легко автоматизировать. Давайте разбираться!
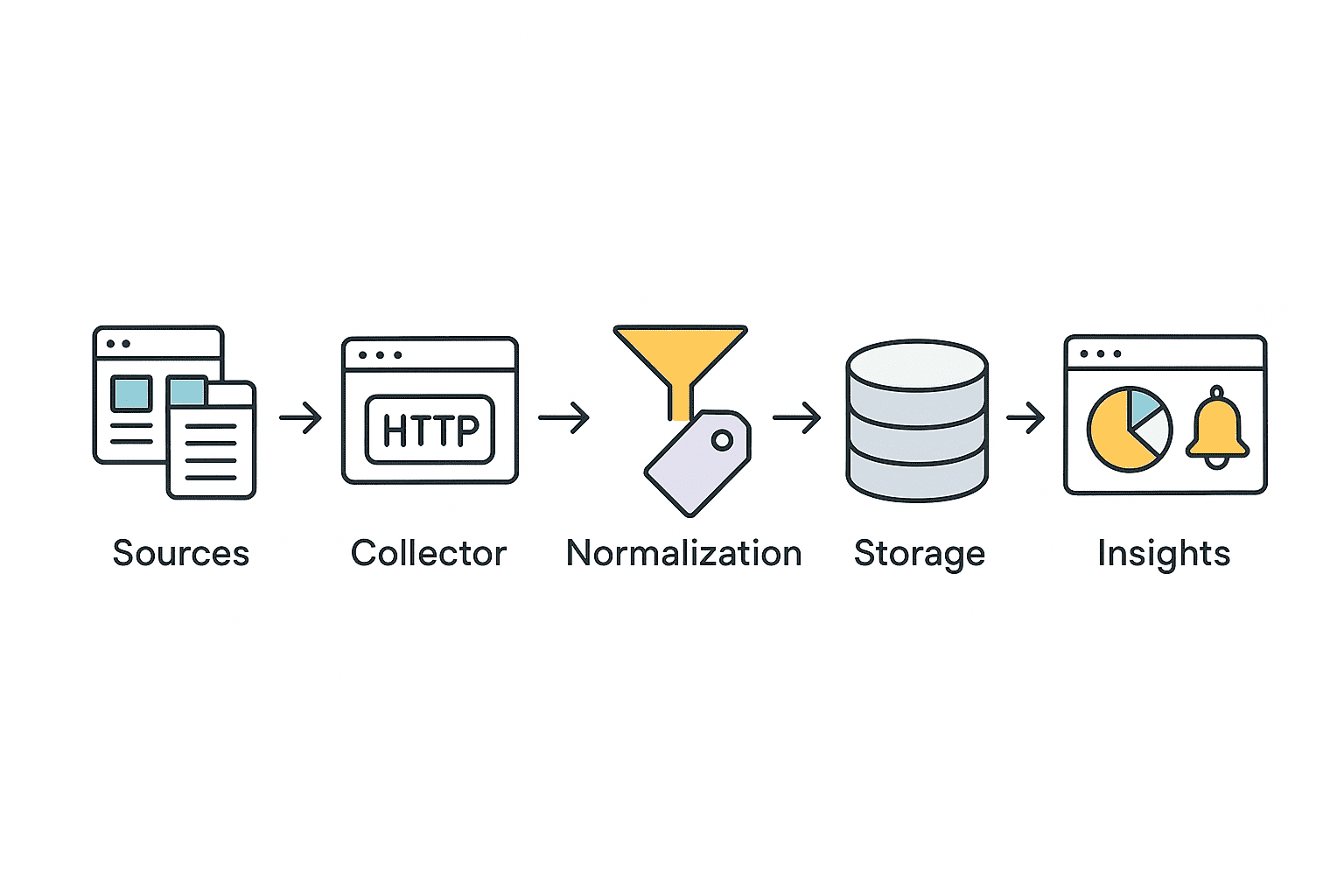
За основу возьмем простой сценарий
- Берём список товаров или категорий и план обновлений: раз в день для базового мониторинга или раз в час для высококонкурентных ниш.
- Для каждой карточки вытаскиваем “коммерческие поля”: цена, валюта, наличие, доставка, скидка, продавец.
- Собираем отзывы: рейтинг, текст, дата, полезность, а также признаки проблем (доставка, качество, гарантия).
- Сверяем с трендами: растет ли интерес к категории/бренду/модели, и совпадает ли это с динамикой цен и отзывов.
- Складываем всё в хранилище и строим алерты: “цена упала на 7%”, “всплеск негатива по доставке”, “категория пошла в рост”.
Сбор цен
Парсинг цен с сайтов конкурентов или агрегаторов - классическая задача. Чаще всего цены находятся в статическом HTML (кроме SPA-приложений). Для простых случаев достаточно сделать GET-запрос через requests и распарсить ответ BeautifulSoup:
python
import requests
from bs4 import BeautifulSoup
url = "https://example.com/product/123"
headers = {"User-Agent": "Mozilla/5.0"} # иногда требуется подделать User-Agent
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, 'html.parser')
price = soup.select_one(".product-price").text.strip()
print("Price:", price)Такой код извлечет цену из HTML-страницы. Понятно, что это идеальный вариант, когда нет никаких преград. В любом случае, важно проверять наличие элементов и обрабатывать исключения (на случай блокировок или изменений разметки). А если цены генерируются через JavaScript, может дополнительно понадобиться рендеринг страницы.
- Для периодической проверки цен удобно обойти списки товаров (
for page in category: ...). - Собранные данные можно сохранять в CSV/JSON или БД.
Какие поля стоит сохранять (чтобы потом не переделывать)
Для цен полезно фиксировать не только “price”, но и контекст:
- итоговую цену и старую цену (если есть скидка);
- валюту, единицу (шт/кг/л), НДС (если явно указан), стоимость доставки;
- наличие (in stock / out of stock / pre-order) и срок доставки;
- идентификаторы: URL, домен, SKU/артикул (если есть), название товара;
- дату и время снимка, а также источник (сайт/категория/поисковая выдача).
Это превращает сбор из “вытащил число” в датасет, на котором можно строить нормальные сравнения и графики.
Ну а частые запросы лучше распределять по разным прокси, чтобы не превышать лимиты и не нарваться на блокировку.
Когда хватит requests, а когда нужен рендер
requests + BeautifulSoup отлично работают, если:
- цена и нужные поля присутствуют в HTML сразу;
- нет обязательной авторизации;
- сайт не требует активной сессии и не режет частые запросы.
Нужен браузерный рендер (Playwright/Selenium или облачный браузер), если:
- в HTML приходит “каркас”, а данные подтягиваются через JS;
- контент появляется только после прокрутки, кликов “показать ещё”, фильтров;
- страница зависит от географии, cookie или состояния сессии.
Сбор отзывов
Отзывы о товарах/услугах часто публикуются на страницах продуктов или агрегаторов (Trustpilot, Яндекс.Маркет, Google Reviews). Иногда эти данные можно получить как статический HTML, но нередко отзывы загружаются динамически или требуют клика по кнопке "еще". Простейший способ - как и с ценами, использовать requests + BeautifulSoup:

python
url = "https://example.com/product/123/reviews"
res = requests.get(url, headers={"User-Agent": "Mozilla/5.0"})
soup = BeautifulSoup(res.text, 'html.parser')
reviews = [rv.get_text(strip=True) for rv in soup.select(".review-text")]
print("Found reviews:", reviews)Однако если сайт подгружает отзывы через JS (например, при прокрутке или AJAX-запросом), статический запрос не даст полного списка. В таких случаях можно применить браузерную автоматизацию, вот пример на Playwright:
python
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto("https://example.com/product/123/reviews")
# Ждём появления элементов или прокручиваем, если нужно
page.wait_for_selector(".review-text")
reviews = [el.inner_text().strip() for el in page.query_selector_all(".review-text")]
print("Reviews:", reviews)
browser.close()Playwright (и Selenium, кстати тоже) рендерит JavaScript, поэтому гарантированно получает динамически загружаемый контент. Однако такие решения тяжелее и медленнее обычного HTTP-запроса. Для накопления большого числа отзывов может потребоваться серьезная инфраструктура и ротация прокси.
Качество данных важнее, чем кажется
Даже если парсер “что-то собрал”, аналитика может поехать из-за мелочей. Минимальный набор практик:
- Нормализация: приводите цену к одной валюте, единице измерения и формату числа; отдельно храните цену и доставку.
- Дедупликация: один и тот же товар может встречаться под разными URL или у разных продавцов - нужны правила сопоставления.
- Проверки на выбросы: резкое падение цены на 60% часто означает ошибку селектора, промо-баннер вместо цены или смену разметки.
- Контроль полноты: доля пустых цен/отзывов по источнику - самый простой индикатор, что сайт начал “резать” сбор.
- Логи ошибок: фиксируйте коды ответов (403/429/5xx), таймауты и частоту ретраев — это поможет быстро понять, что именно сломалось.
Сбор трендов
Тренды рынка - это либо статистика поисковых запросов, либо популярные товары/темы. Источники трендов могут быть разными: Google Trends, соцсети, сервисы аналитики. С помощью библиотеки pytrends можно получить тренды Google:
python
from pytrends.request import TrendReq
pytrends = TrendReq(hl='ru-RU', tz=360)
trending = pytrends.trending_searches(pn='russia') # или 'world'
print(trending.head())Если же тренды представлены на динамической странице (как вариант - лента горячих запросов Google Trends или соцсетей), можно опять использовать Playwright для рендера:
python
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto("https://trends.google.com/trends/trendingsearches/daily?geo=RU")
titles = [el.inner_text() for el in page.query_selector_all(".details-top > div.title")]
print("Trending searches:", titles)
browser.close()Идея в том, что любая публично доступная информация может быть добыта парсингом. Тренды можно также извлекать из API, но многие предпочитают их собирать напрямую со страниц.
Устойчивый сбор публичных данных: ограничения и практики
Когда сбор становится регулярным и масштабным, главная проблема - не “как спарсить HTML”, а как сделать процесс устойчивым: чтобы он работал неделями, не падал из-за мелких изменений и не превращался в постоянную ручную поддержку.

Когда сбор становится регулярным и масштабным, главная проблема - не “как спарсить HTML”, а как сделать процесс устойчивым: чтобы он работал неделями, не падал из-за мелких изменений и не превращался в постоянную ручную поддержку.
Практическая цель здесь одна: получать публично доступные данные стабильно, соблюдая правила источников и не создавая излишнюю нагрузку.
Чтобы снизить число отказов и сделать сбор устойчивым, обычно используют комбинацию практик:
- Рендеринг. Настоящий браузер (Selenium/Playwright) или облачный браузерный API, такой есть у Scrapeless, помогает корректно получать данные со страниц, где контент формируется JavaScript’ом и зависит от состояния сессии.
- Ротация IP и географии. Распределение запросов по пулу адресов помогает не упираться в лимиты источника и уменьшает долю 429/403 при регулярном мониторинге.
- Управление запросами. Реалистичные заголовки, корректная работа с cookies/сессиями, таймауты, ретраи и паузы между запросами уменьшают “шум” и делают поведение ближе к обычному пользователю.
- Проверки доступности. Если источник вводит дополнительную проверку (например, CAPTCHA), её обработка - распознавание капчи, должна быть частью пайплайна - иначе сбор будет ломаться на случайных участках.
- Облачные API для веб-сбора. Готовые решения берут на себя рендер, сетевую часть, ретраи и прокси-слой, чтобы вы концентрировались на данных и аналитике, а не на инфраструктуре.
Как выбрать правильный подход
- Если нужные данные видны в исходном HTML и объём небольшой - начинайте с requests + BeautifulSoup. Это быстрее всего и проще поддерживать.
- Если данные появляются после выполнения JavaScript, кликов или прокрутки - используйте Playwright: он даёт полный рендер страницы и подходит для динамических сценариев.
- Если задача упирается в масштаб, стабильность и инфраструктуру (много источников, много параллельных запросов, постоянные блокировки, капчи, прокси-пул, ретраи) — имеет смысл вынести рендер и сетевую часть в облачный слой.
Когда рекомендуется использовать Scrapeless:
- Scraping Browser полезен, когда нужен Playwright-подход, но не хочется поднимать и обслуживать собственные браузерные фермы.
- Universal Scraping API подходит, когда важны стабильные ответы для сложных страниц, и вы хотите “запрос → результат” без ручной настройки рендера.
- Дополнительные компоненты вроде прокси и решения капч закрывают сетевую рутину, которая обычно съедает больше времени, чем сам парсинг.
Инструменты парсинга: сравнение популярных решений
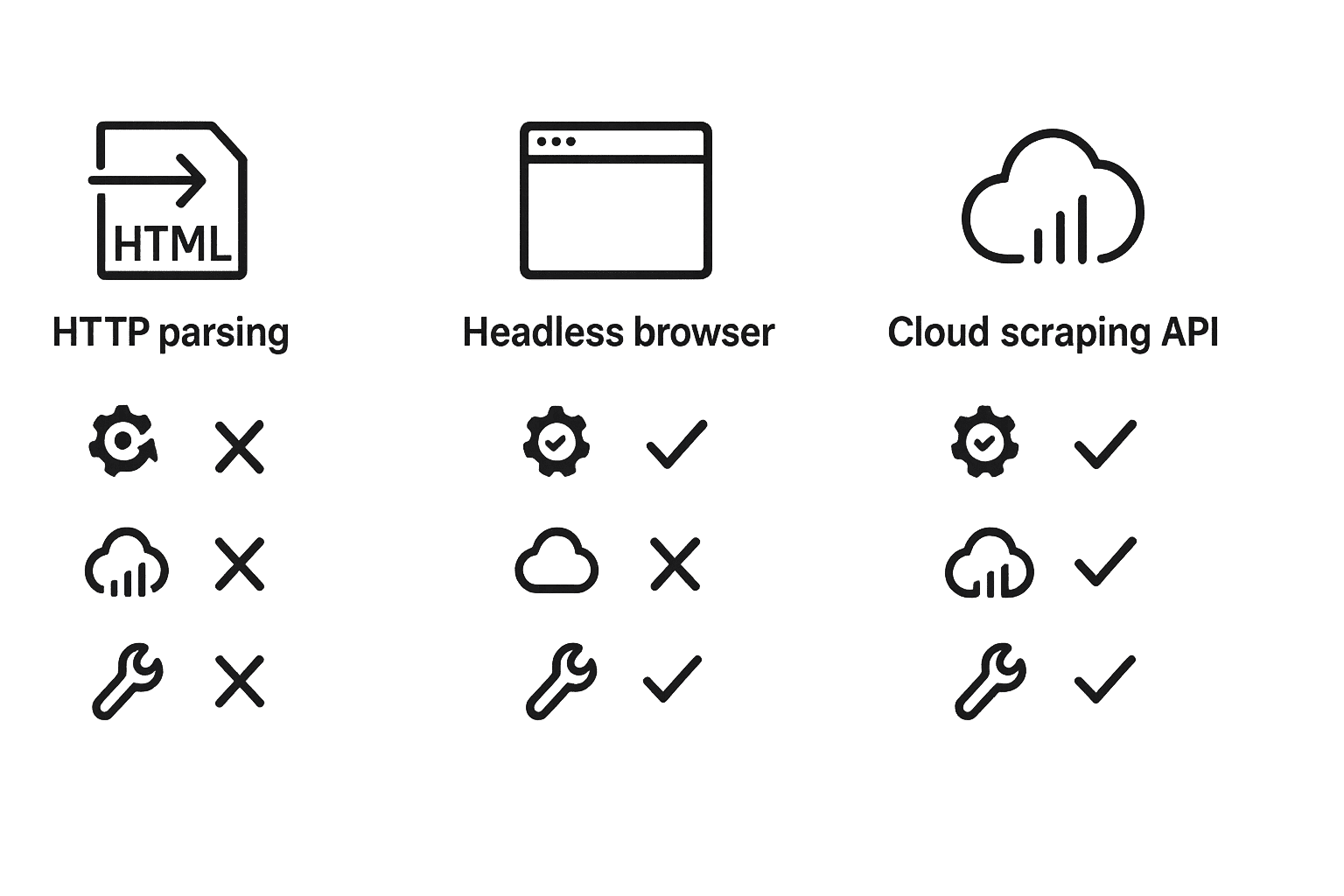
| Инструмент | Тип | Динамический JS | Прокси/антибот | Скорость | Комментарий |
|---|---|---|---|---|---|
| requests + BS4 | HTTP-библиотека и парсер HTML | Нет | Нет (нужно вручную) | Очень быстрая | Легкий и простой, подходит для статических страниц, не справляется с JS |
| Scrapeless API | Облачный браузер/скрапинг-сервис | Да (встроен) | Встроенная ротация IP, распознавание капчи | Очень быстрая | Облачное решение: рендерит JS, меняет IP, решает капчу автоматически |
| Scrapy | Асинхронный скрапер (Python) | Нет (для JS нужен Splash) | Через middleware, нужна настройка | Быстрая | Масштабируемый фреймворк для больших проектов |
| Selenium | Браузерная автоматизация | Да | Настраиваемые прокси | Медленная | Универсальный (любой JS) но ресурсоёмкий |
| Playwright | Браузерная автоматизация (новее) | Да | Настраиваемые прокси | Выше Selenium | Более быстрый, поддерживает параллельные контексты |
| PyTrends, APIs | Специализированные API | Нет | Да | Быстрая | Упрощают задачи (Google Trends и т.д.), но не общие |
Каждый инструмент имеет свои плюсы и минусы. Scrapy отлично подходит для серийного парсинга статичных сайтов, Selenium/Playwright - когда нужен полный рендер, Scrapeless и другие облачные API - когда нужно сразу решить проблемы антибот-защиты (Scrapeless "обернёт" ваш запрос через собственный браузер, автоматически, когда нужно снизить долю отказов и снять с команды инфраструктурные задачи (рендер, сетевые ретраи, прокси-слой, обработка проверок доступа).
Выводы и рекомендации
Парсинг цен, отзывов и трендов - важный инструмент аналитика. Для начала простого проекта достаточно requests и BeautifulSoup: они легки в освоении и быстры на статичных страницах. Если страницы динамические, подключайте браузерное решение (Selenium или Playwright). Для серьёзных проектов стоит использовать фреймворк Scrapy (он масштабируется и имеет удобные "паучьи" API) или комбинировать несколько подходов.
Обход антибот-защиты требует дополнительных усилий: прокси и ротация должны быть частью инфраструктуры, а заголовки запросов - "человечными". Рекомендуем переложить эти задачи на профессиональные API (как Scrapeless) - они сами решат капчу и сменят IP.
Шаг 1: выберите 20–50 товаров и один источник, соберите поля цены и наличия, сохраните снимки 3–5 дней подряд. Цель - убедиться, что данные стабильны и пригодны для сравнения.
Шаг 2: добавьте отзывы и заведите простую классификацию проблем по ключевым темам (доставка, качество, гарантия). Уже на этом этапе появятся полезные сигналы.
Шаг 3: подключите тренды для категории/бренда, чтобы понимать, где рост спроса объясняет изменения цен и отзывов.
Шаг 4: масштабируйте до нужного объёма, параллельно добавляя контроль качества (полнота, выбросы, коды ответов) и алерты. Это дешевле, чем “чинить всё в конце”, когда источников станет много.
Итоговые рекомендации:
- Тестируйте подход на небольшом объеме перед масштабированием.
- Используйте прокси для снижения риска блокировки (особенно для параллельных запросов).
- Соблюдайте этикет парсинга - медленные запросы, человекоподобные заголовки, respect robots.txt как минимум.
- Следите за обновлениями сайтов - они могут менять структуру или усиливать защиту.
- Рассмотрите облачные сервисы для экономии времени: они обеспечат рендеринг и антибот-сборку "из коробки".
В итоге грамотный парсинг позволяет получить ценную информацию для принятия решений на рынке. Выбрав подходящие инструменты и соблюдая правила, аналитик может эффективно "раскопать" инсайты из открытых данных и избежать банов.