Решение hCaptcha с обновлениями в методе Grid
Мы рады сообщить о последних обновлениях в методе Grid для решения captcha с помощью нашего сервиса. В этой статье мы подробно рассмотрим, как использовать обновленный API для решения hCaptcha. Этот метод решения hCaptcha актуален, когда не работает решение токеном.
Изменения в методе Grid были нужны для дифференцирования подходов к решению капч сеткой, а использование "компьютерного зрения" в сочетании с традиционным распознаванием работниками позволяет распознавать капчи быстрее и с более высокой точностью.
Что такое hcaptcha?
hCaptcha использует различные типы тестов для проверки того, что пользователь является человеком. В статье мы рассмотрим случай, когда задача представляет собой сетку, содержащую 9 изображений.
Какие изменения были в API?
Теперь метод Grid принимает дополнительный параметр imgType, который используется для направления запроса в соответствующий поток распознавания в соответствии с типом капчи. При решении типа hCaptcha необходимо присвоить параметру imgType, значение hcaptcha.
Как распознать капчу с помощью Grid-метода?
Процесс распознавания условно делится на 4 шага:
- Клик на чекбокс капчи
- Извлечение необходимые данные капчи
- Взаимодействие с API
- Отмечание нужных квадратов сетки
Чтобы кликнуть на капчу, а затем на картинки в области сетки, вы можете использовать соответствующие методы платформы автоматизации браузера на ваш выбор.
В этой статье мы сосредоточимся на втором и третьем шагах.
Сбор данных
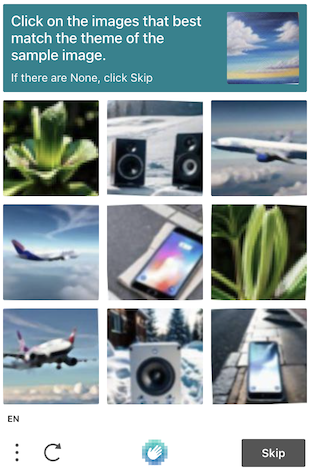
Задание hCaptcha состоит из:
- девяти изображений
- текста задачи
- изображение задания (опционально)
Получить все элементы изображений можно с помощью селектора 'div.image:not([role="img"])' внутри фрейма капчи. Последние 9 элементов — это плашки, которые мы затем объединим в одно изображение с сеткой 3x3. Первое изображение, если оно присутствует, — это изображение задачи.
Вот что из этого получится.
9 изображений, склеенных вместе

Картинка задания

Для получения текста задания воспользуемся селектором 'h2.prompt-text', чтобы получить элемент h2 и элемент innerText. Убедитесь в том, что язык вашего браузера English, так как мы предполагаем, что текст задания предоставлен на английском языке.
В нашем случае текст выглядит следующим образом:
Click on the images that best match the theme of the sample image.Ниже приведена функция на JavaScript, которая поможет извлечь данные корректно. Вы можете использовать этот код в iframe капчи после того как нажмёте на чекбокс капчи. Когда задание капчи станет видимым, вызовите функцию getCaptchaData. Функция возвращает Promise, который будет являться объектом, содержащим следующие свойства:
type- тип задания API:GridTaskилиCoordinatesTask. В статье мы рассматриваем случайGridTaskbody- склеенные вместе плашки или весь набор задания для типаCoordinatesTaskв формате строки base64comment- текст заданияimgInstructions- изображение задания в виде строки base64 (опционально)
Пример использования функции:
try {
let data = getCaptchaData()
console.log(JSON.stringify(data))
} catch (e) {
console.error(e)
}Код функции
class Tile {
constructor(el) {
this.url = el.style['backgroundImage'].slice(5, -2)
this.width = el.clientWidth
this.height = el.clientHeight
this.img = new Image(this.width, this.height)
this.img.setAttribute('crossorigin', 'anonymous')
}
load(ctx, index = 0, vOffset = 0) {
return new Promise((resolve) => {
let pos = [
{ x: 0, y: 0 }, { x: ctx.canvas.width / 3, y: 0 }, { x: ctx.canvas.width / 3 * 2, y: 0 },
{ x: 0, y: ctx.canvas.height / 3 }, { x: ctx.canvas.width / 3, y: ctx.canvas.height / 3 }, { x: ctx.canvas.width / 3 * 2, y: ctx.canvas.height / 3 },
{ x: 0, y: ctx.canvas.height / 3 * 2 }, { x: ctx.canvas.width / 3, y: ctx.canvas.height / 3 * 2 }, { x: ctx.canvas.width / 3 * 2, y: ctx.canvas.height / 3 * 2 }
]
this.img.addEventListener('load', () => {
ctx.drawImage(this.img, pos[index].x, vOffset + pos[index].y)
resolve(this.img)
})
this.img.src = this.url
})
}
}
const getMaxTileSize = (nodes) => {
return nodes.reduce((m, c) => {
return {
width: !m.width || c.clientWidth > m.width ? c.clientWidth : m.width,
height: !m.height || c.clientHeight > m.height ? c.clientHeight : m.height
}
})
}
const getCaptchaData = () => {
return new Promise((resolve, reject) => {
let canvas, taskCanvas, result = {}
const imgNodes = Array.from(document.querySelectorAll('div.image:not([role="img"])'))
const comment = document.querySelector('h2.prompt-text').innerText
if (imgNodes.length < 9) {
const srcCanvas = document.querySelector('canvas')
let tmpcanvas = document.createElement('canvas')
tmpcanvas.width = srcCanvas.clientWidth
tmpcanvas.height = srcCanvas.clientHeight
let tmpctx = tmpcanvas.getContext('2d')
tmpctx.drawImage(srcCanvas, 0, 0, srcCanvas.width, srcCanvas.height, 0, 0, tmpcanvas.width, tmpcanvas.height)
tmpctx.font = "18px sans-serif";
tmpctx.fillText(comment, 4, 20, tmpcanvas.width - 8);
let promises = []
imgNodes.forEach((imgNode, i) => {
const tile = new Tile(imgNode, tmpctx)
promises.push(tile.load(tmpctx, i, imgNode.clientHeight / 4))
})
Promise.all(promises).then(() => {
result = {
comment,
body: tmpcanvas.toDataURL().replace(/^data:image\/?[A-z]*;base64,/, ''),
type: 'CoordinatesTask'
}
resolve(result)
})
} else if (imgNodes.length >= 9) {
result.type = 'GridTask'
result.comment = comment
const maxTileSize = getMaxTileSize(imgNodes)
const tileNodes = imgNodes.filter(n => (n.clientWidth >= maxTileSize.width && n.clientHeight >= maxTileSize.height))
canvas = document.createElement('canvas')
canvas.width = maxTileSize.width * 3
canvas.height = maxTileSize.height * 3
let ctx = canvas.getContext('2d')
let promises = []
tileNodes.forEach((tileNode, i) => {
const tile = new Tile(tileNode, ctx)
promises.push(tile.load(ctx, i))
})
Promise.all(promises).then(() => {
result.body = canvas.toDataURL().replace(/^data:image\/?[A-z]*;base64,/,'')
})
if (imgNodes.length > 9) {
const maxTileSize = getMaxTileSize(imgNodes)
const [taskNode] = imgNodes.filter(n => (n.clientWidth < maxTileSize.width && n.clientHeight < maxTileSize.height))
taskCanvas = document.createElement('canvas')
taskCanvas.width = taskNode.clientWidth
taskCanvas.height = taskNode.clientHeight
let taskCtx = taskCanvas.getContext('2d')
const taskTile = new Tile(taskNode, taskCtx, 0)
taskTile.load(taskCtx).then(() => {
result.imgInstructions = taskCanvas.toDataURL().replace(/^data:image\/?[A-z]*;base64,/, '')
})
}
resolve(result)
} else {
reject(`Unknown captcha type. Image nodes count: ${imgNodes.length}`)
}
})
}Пример результата
{
"type": "GridTask",
"comment": "Click on the images that best match the theme of the sample image.",
"imgInstructions": "iVBORw0KGgoAAA...",
"body": "iVBORw0KGgoAAAA..."
}Взаимодействие с API
Когда собраны все необходимые данные, отправляется запрос к API для решения капчи. Используются данные, полученные на предыдущем этапе, добавляется параметр imgType со значением hcaptcha, а также указываетсяколичество столбцов и строк, в нашем случае оба имеют значение 3.
Метод: POST
API endpoint: https://api.rucaptcha.com/createTask
Параметры
| Параметр | Тип | Обязательный | Описание |
|---|---|---|---|
| type | String | Да | Тип задачи, в нашем случае GridTask |
| imgType | String | Да | В нашем случае hcaptcha |
| body | String | Да | Склеенные в одно изображение плашки в формате base64 |
| comment | String | Да | Текст задания на английском языке |
| rows | Number | Да | Количество строк, в нашем случае 3 |
| columns | Number | Да | Количество столбцов, в нашем случае 3 |
| imgInstructions | String | Нет | Изображение задания в формате base64 |
Пример запроса
{
"clientKey":"YOUR_API_KEY",
"task": {
"type": "GridTask",
"imgType": "hcaptcha",
"body": "iVBORw0KGgoAAAA...",
"comment": "Click on the images that best match the theme of the sample image.",
"rows": 3,
"columns": 3,
"imgInstructions": "iVBORw0KGgoAAA..."
}
}Результат выполнения запроса
{
"errorId": 0,
"status": "ready",
"solution": {
"click": [
3,
4,
7
]
},
"cost": "0.0012",
"ip": "1.2.3.4",
"createTime": 1692863536,
"endTime": 1692863556,
"solveCount": 1
}Используйте метод click вашего фреймворка автоматизации браузера для клика по соответствующим элементам. Используйте селектор для элементов 'div.task', только помните, что массив элементов картинок нумеруется с 0, а в ответе нашего API картинки нумеруются с 1 по 9. В нашем примере мы кликаем по ним с помощью чистого JavaScript:
document.querySelectorAll('div.task')[3-1].click()
document.querySelectorAll('div.task')[4-1].click()
document.querySelectorAll('div.task')[7-1].click()Также вы можете использовать наши библиотеки для быстрой реализации метода в вашем решении.
Примеры кода в наших библиотеках
Ruby
result = client.grid({
method: 'base64',
key: 'your_api_key',
recaptcha: 1,
json: 1,
recaptchacols: 3,
recaptcharows: 3,
img_type: 'hcaptcha',
textinstructions: 'lease click on all entities similar to the following silhouette',
imginstructions: Base64.encode64(File.read('path/to/hint.jpg')),
body: Base64.encode64(File.read('path/to/captcha.jpg')),
previous_id: 0
})Python
result = solver.grid( method='base64',
body = 'base64',
key='your_api_key',
recaptcha=1,
json=1,
recaptchacols=3,
recaptcharows=3,
img_type='hcaptcha',
textinstructions='Please click on all entities similar to the following silhouette',
imginstructions=base64.b64encode(open('path/to/hint.jpg', 'rb').read()).decode('utf-8'),
previous_id=0)
</details>